An AI-powered ATS that simplifies shortlisting, tagging, and workflows - built for fast, scalable, and collaborative hiring.
Landing Pages
Copyright © 2026|hiremore AI
An AI-powered ATS that simplifies shortlisting, tagging, and workflows - built for fast, scalable, and collaborative hiring.




The market for AI recruitment tools has exploded past a thousand vendors, and most demos look identical: a slick ranking screen, a bold accuracy claim, a testimonial from a logo you recognize. AI recruitment tools are software products that use machine learning to screen, rank, match, or communicate with candidates across the hiring process, and the gap between the best and the worst of them is enormous.
This guide is for hiring leaders and recruiters evaluating a purchase. You’ll get the 7 questions that separate real capability from demo theater, the compliance checks that are now legally required in several jurisdictions, and a 30-day pilot structure that produces a defensible buy decision.
Buying wrong is expensive in a specific way: the average mid-market team spends 4 to 6 months implementing a recruitment tool. Choose badly and that’s half a year of change management spent installing a problem.
- The single most important test for AI recruitment tools is explainability: if the vendor can’t show why a specific candidate ranked where they did, walk away.
- Bias audit documentation is now a legal requirement in some jurisdictions: NYC Local Law 144 mandates annual independent audits for automated employment decision tools, and the EU AI Act classifies hiring AI as high-risk.
- A structured 30-day parallel pilot, running the tool against your current process on the same live roles, produces a real buy decision; demos and references don’t.
- Accuracy claims without a baseline are marketing. “95% accurate” means nothing unless the vendor defines accurate against what, measured on whose data.
- Expect total first-year cost to run 1.5 to 2x the license fee once implementation, integration, and training are counted.
AI recruitment tools are software products that apply machine learning to hiring tasks: screening and ranking candidates, parsing resumes, scheduling interviews, running structured assessments, and automating candidate communication.
The category covers four broad families. Screening and ranking tools score candidates against role criteria. Sourcing tools find and engage passive candidates. Assessment tools measure skills through tests, work samples, or structured AI interviews — if you’re considering the last of these, The Complete Guide to AI-Powered Interviews covers how they work in depth. Workflow tools automate logistics like scheduling, status updates, and posting.
The families differ in risk. A scheduling bot that books the wrong room is an inconvenience. A ranking model that systematically downgrades a protected group is a lawsuit. The closer a tool sits to a hiring decision, the higher the bar it has to clear on explainability and auditability, which is exactly where this guide focuses.
Explainability: the tool’s ability to show the specific reasons behind each score or ranking.Bias audit: an independent statistical review of whether the tool’s outputs disadvantage protected groups.Parallel pilot: running a new tool alongside your existing process on the same candidates to compare outcomes directly.Tool selection matters because an AI recruitment tool isn’t a utility you swap out casually: it shapes who gets seen, costs 4 to 6 months to implement, and carries compliance obligations that land on you, not the vendor.
The asymmetry buyers miss is that switching costs compound. Your team builds workflows around the tool, your historical data accumulates inside it, and your recruiters learn its quirks. Two years in, replacing a mediocre tool costs more than choosing well would have. Teams that rushed selection report living with known problems for 3+ years because migration felt worse.
The legal dimension has also stopped being theoretical. Under NYC Local Law 144, employers using automated employment decision tools owe candidates notice and the public an annual bias audit. The EU AI Act places hiring systems in its high-risk category with documentation and oversight duties. In both regimes, the obligation sits with the employer using the tool. “Our vendor said it was fine” is not a defense.
None of this works in isolation either — tool selection is only one part of a larger picture. If you haven’t yet mapped out how AI fits your overall hiring function, Building an AI-First Recruitment Strategy from Scratch is a useful starting point before committing to any vendor.
📊 Key Stat: Industry implementation surveys consistently put mid-market recruitment tool rollouts at 4 to 6 months from contract to full adoption. The selection mistake you make in a 2-week evaluation costs you a half-year to install and years to unwind.
The capabilities that separate good AI recruitment tools from demo theater are per-decision explainability, published bias audits, native integrations with your stack, and data portability, in that order.
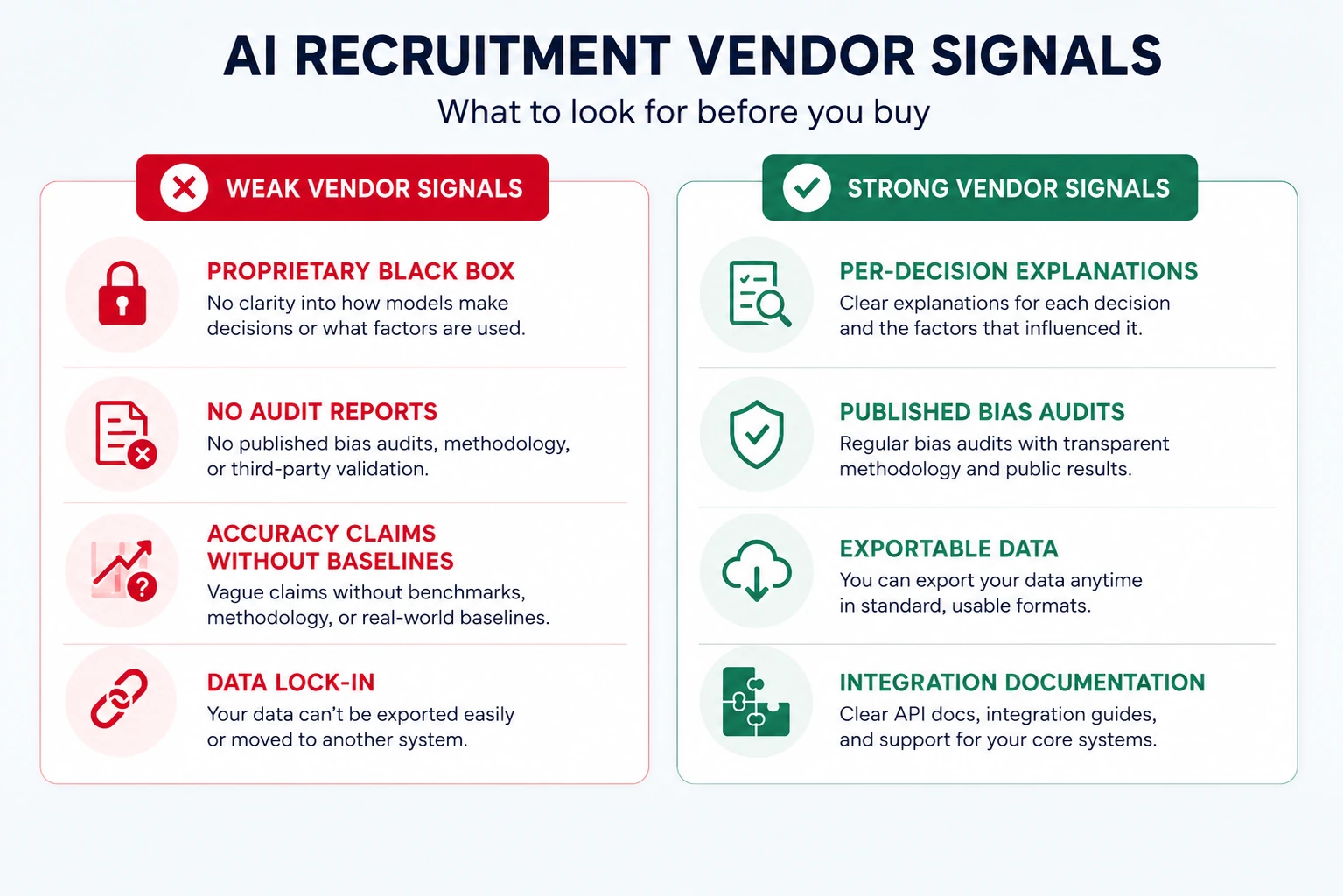
Per-decision explainability. The tool should answer “why is this candidate ranked 4th?” with specific, criteria-linked reasons. This is what makes rankings reviewable by recruiters, defensible to candidates, and auditable by regulators. Black-box scores fail all three. To understand exactly how the underlying screening mechanics work, How AI Resume Screening Works (and How to Get It Right) breaks it down in detail.
Published bias audit results. Strong vendors run independent audits and share results without being cornered. Weak vendors say “our model is bias-free by design,” which is a sentence no serious ML practitioner utters.
Native integration with your ATS. A tool that lives outside your workflow gets abandoned. Check for real, supported, bidirectional integration with your specific ATS version, not a logo on a partners page. Integration failures are the most commonly cited reason recruitment tools end up as shelfware. If you’re still deciding which ATS sits at the centre of your stack, How to Choose the Right ATS for Your Hiring Team covers that evaluation in full before you add an AI layer on top.
Data portability. Your candidate data, scores, and audit logs should be exportable in standard formats at any time. Lock-in turns a bad tool decision into a hostage situation.
Configurable criteria, not inferred ones. You want a tool that ranks against the must-haves you define, not one that infers “good” from your historical hires and quietly replicates old patterns. This also shapes what you should and shouldn’t hand to automation — AI Hiring Automation: What to Automate and What Not To is worth reading before you configure which parts of the funnel the tool owns.
| Capability | Strong Signal | Weak Signal |
|---|---|---|
| Explainability | Per-candidate, criteria-linked reasons | A single opaque score |
| Fairness | Independent audit reports, on request | “Bias-free by design” claims |
| Integration | Bidirectional sync with your ATS, documented | “API available” and nothing else |
| Data | Full export, standard formats, contractual right | Proprietary formats, export fees |
| Criteria | You define must-haves; tool scores against them | Model infers fit from past hires |
💡 Pro Tip: In the demo, point at any ranked candidate and ask “why this position?” Then point at a lower-ranked one and ask what would change their rank. Vendors with real explainability answer instantly. The rest improvise, and you’ll hear it.
Evaluate AI recruitment tools in three passes: 7 hard questions to shortlist vendors, a compliance check to eliminate the unbuyable, and a 30-day parallel pilot on live roles to make the final call.
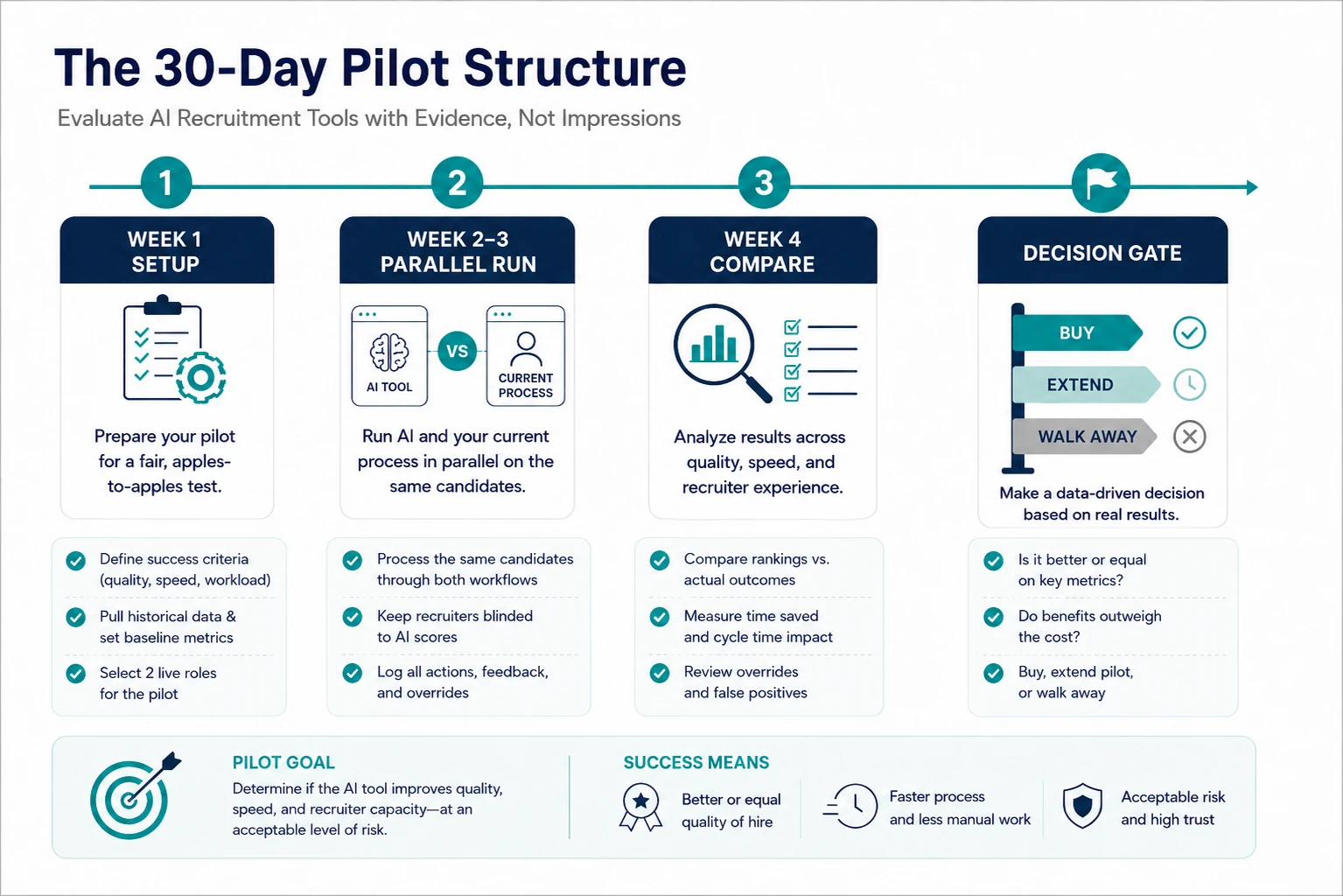
Input: Your shortlist of 3 to 5 vendors, one structured call each.
Process: Ask every vendor the same questions: 1. How does the model explain individual rankings? 2. What did your last independent bias audit find, and can we see it? 3. What data was the model trained on? 4. How does it handle candidates with non-traditional backgrounds? 5. What’s the documented integration path for our ATS? 6. What happens to our data if we leave? 7. What’s a realistic accuracy baseline on our data, not your benchmark set?
Output: Usually 1 to 2 vendors survive with credible answers to all seven.
Input: Surviving vendors’ audit reports, DPAs, and documentation.
Process: Verify bias audit recency and independence, data processing terms against your privacy obligations, and candidate notice workflows where law requires them (LL144 today, EU AI Act phasing in). Involve counsel for an hour now rather than a deposition later.
Output: Vendors you’re legally comfortable deploying.
Input: 2 to 3 live requisitions, your written must-have criteria, the finalist tool.
Process: Run the tool alongside your current process on the same candidates. Recruiters review AI rankings against their own judgments weekly. Track agreement rate, time saved, override reasons, and any pass-rate anomalies by group.
Output: A decision backed by your own data: buy, extend the pilot, or walk away.
The highest-impact practice is writing your evaluation criteria and success metrics before the first demo, because demos are professionally designed to set your criteria for you.
Define success before demos. Before: the team sees five demos and falls for the best presenter. After: a written scorecard (explainability, audit quality, integration, pilot results, cost) forces every vendor through the same gate. Decision time drops and regret drops with it.
Involve recruiters from day one. Before: leadership buys, recruiters resent, adoption stalls at 30%. After: two working recruiters sit in every demo and co-own the pilot. Adoption climbs because the tool was chosen by the people who use it.
Price the total, not the license. Before: a $40k license becomes a $75k year-one surprise. After: implementation, integration work, training, and audit costs are priced into the comparison from the start. Expect 1.5 to 2x license fee in year one.
Reference-check the failure cases. Before: vendors hand you their three happiest customers. After: you ask each reference “what almost made you churn?” and ask the vendor for a customer who left. The answers are where the truth lives.
| Condition | Recommended Action | Expected Outcome |
|---|---|---|
| High volume (100+ apps/role), first AI purchase | Start with screening + scheduling tools, pilot on 2 roles | Fast payback, low decision risk |
| Existing ATS, adding AI layer | Weight integration 2x in scorecard | No shelfware |
| Regulated industry or NYC/EU exposure | Compliance check before any pilot | No unbuyable finalists |
| Niche, low-volume hiring | Reconsider: assist tools only, skip ranking | Money saved on a problem you don’t have |
⚠️ Watch Out: Never sign a multi-year contract before the pilot. Vendors discount hard for 3-year commitments precisely because switching costs do their retention work for them. A 1-year term with a pilot exit clause is worth more than the discount.
The most common buying failure is evaluating tools on demo data instead of your own, which hides exactly the weaknesses you’ll discover after the contract is signed.
Demos run on curated data tuned to impress. Solution: insist on a sandbox loaded with your own anonymized resumes and a real job description from your backlog. Tools differ visibly within an hour on real data.
Security reviews, legal, and budget cycles stretch evaluations until champions lose energy. Solution: run security and legal checks on your top 2 in parallel with the pilot, not after it. Compress the calendar, not the diligence.
“95% accuracy” against an undefined benchmark is unfalsifiable. Solution: make the pilot the only accuracy test that counts, and define the measure upfront: agreement with your best recruiters’ judgments on your candidates.
Adoption, not capability, kills most tool investments. Solution: tie rollout to one painful workflow (usually scheduling or first-pass screening), show the time saved in week one, and expand from the win.
Teams that pilot before buying consistently avoid the expensive mistake, and teams that weight integration heavily get to value fastest.
E-commerce scale-up, 200 hires/year. Problem: shortlisted two screening tools that looked identical in demos. Intervention: a 30-day parallel pilot on three live roles, tracking recruiter agreement rates. Tool A agreed with senior recruiter judgments 78% of the time, Tool B 54%, and Tool B’s misses clustered on career-changers. Measured outcome: bought Tool A, avoided a mis-purchase, and cut screening time 60% in the first quarter.
Regional bank, compliance-heavy hiring. Problem: a promising vendor couldn’t produce an independent bias audit. Intervention: made the audit a hard gate per their LL144 exposure; vendor declined, bank walked. Measured outcome: the vendor’s tool was later flagged publicly in a regulatory complaint, and the bank’s gate had cost them nothing but a demo hour.
Healthcare staffing firm, 5,000 placements/year. Problem: previous AI tool became shelfware because it didn’t sync with their ATS. Intervention: re-ran selection with integration weighted double and a contractual data-export clause. Measured outcome: 85% recruiter adoption at 90 days versus 25% on the prior tool, and 11 hours saved per recruiter per week.
💡 Pro Tip: The bank case is the pattern to remember: a hard compliance gate costs you one demo hour and occasionally saves you from a vendor whose problems become public later.
The most important post-purchase metric is recruiter adoption rate at 90 days, because a tool nobody uses delivers precisely nothing regardless of its capability.
Adoption rate. Definition: share of target users actively using the tool weekly; the leading indicator of ROI. Calculation: weekly active recruiters ÷ licensed recruiters × 100. Target benchmark: 80%+ at 90 days; below 50% means workflow misfit, not user stubbornness.
Time saved per recruiter. Definition: weekly hours recovered from automated or accelerated tasks. Calculation: before/after time audit on screening, scheduling, and admin tasks. Target benchmark: 8 to 15 hours weekly for screening + scheduling tools.
Override rate. Definition: how often recruiters overrule the tool’s recommendations; measures model-criteria fit. Calculation: overrides ÷ recommendations × 100. Target benchmark: 10 to 25%; near-zero means rubber-stamping, 40%+ means criteria need tuning.
Four-fifths compliance. Definition: adverse impact check on tool-assisted stages. Calculation: lowest group pass rate ÷ highest, quarterly. Target benchmark: ≥ 0.80, documented every quarter.
Funnel speed. Definition: application-to-shortlist time on tool-assisted roles. Calculation: average days, compared to pre-tool baseline. Target benchmark: 40 to 60% reduction for screening tools.
| Metric | What It Measures | How to Calculate | Target Benchmark |
|---|---|---|---|
| Adoption rate | Real usage | Weekly actives ÷ licenses | 80%+ at 90 days |
| Time saved | Efficiency ROI | Before/after time audit | 8 to 15 hrs/week |
| Override rate | Model fit | Overrides ÷ recommendations | 10 to 25% |
| Four-fifths ratio | Fairness | Lowest ÷ highest pass rate | ≥ 0.80 quarterly |
| Funnel speed | Process impact | App-to-shortlist days vs baseline | 40 to 60% faster |
The highest-severity risk is buying a black-box ranking tool: you inherit its biases, you can’t explain its decisions, and regulators hold you responsible for both.
Inherited bias. Models trained on historical hiring data import historical patterns. Demand training-data transparency and independent audits; assume nothing.
Compliance transfer. Every regulation in this space binds the employer. Vendor indemnities help with costs, not with reputational damage or consent decrees.
Lock-in economics. Proprietary data formats and export fees convert dissatisfaction into captivity. Contract for portability before signing, when your leverage peaks.
Capability theater. Some “AI” tools are keyword matchers with a neural-net press release. The explainability question exposes them fastest: keyword matchers can’t explain rankings in criteria terms because there’s no model to explain.
⚠️ Watch Out: If a vendor resists running a pilot on your data, treat it as disqualifying. Confidence shows you the tool on your candidates. Marketing shows you a deck.
The buying landscape is consolidating around audited, explainable platforms, with point solutions either folding into suites or competing on verified compliance.
Audit-first selling. As bias-audit laws spread beyond NYC, audit documentation is shifting from differentiator to entry requirement. Expect RFPs to open with it within a couple of buying cycles.
Agentic tool consolidation. Standalone schedulers, screeners, and outreach tools are merging into agent-style platforms that execute multi-step workflows. Buyers should weigh platform coherence against best-of-breed capability more carefully than in the last cycle.
Outcome-based pricing experiments. A growing minority of vendors price per qualified shortlist or per hire rather than per seat. It aligns incentives, and it makes your metrics (adoption, funnel speed) contractually relevant.
Four things, in order: per-decision explainability, independent bias audit documentation, native integration with your ATS, and contractual data portability. Then verify everything with a 30-day parallel pilot on your own live roles. Demos and references measure salesmanship; pilots measure the tool.
License pricing varies widely, from a few hundred dollars monthly for small-team screening tools to six figures annually for enterprise platforms. Budget 1.5 to 2x the license fee for year one once implementation, integration, and training are counted, and weight total cost, not sticker price, in comparisons.
Above roughly 75 to 100 applications per role, yes: screening and scheduling automation pay back in weeks. Below that volume, the honest answer is usually no for ranking tools, and yes only for lightweight scheduling automation. Buy when volume hurts.
Ask for the most recent independent bias audit and check the four-fifths ratios it reports. Then verify during your pilot: compare pass rates across groups on your own candidate flow. A vendor who claims their tool is “bias-free” without audit evidence is telling you they haven’t measured.
The seven that matter: how rankings are explained, what the last bias audit found, what data trained the model, how non-traditional candidates are handled, the documented integration path for your ATS, what happens to your data at exit, and what accuracy looks like on your data rather than their benchmark.
30 days on 2 to 3 live requisitions is the sweet spot: long enough to cover full screening cycles and surface integration friction, short enough to hold everyone’s attention. Run it parallel to your existing process on the same candidates so the comparison is direct.
Buying AI recruitment tools well comes down to refusing to outsource your judgment to a demo. Write your criteria first, ask the seven questions, gate on compliance, and let a 30-day parallel pilot on your own candidates make the decision.
The tradeoff is real: rigorous evaluation costs you 6 weeks. Skipping it risks 6 months of implementing the wrong tool and years of living with it.
If explainable, auditable AI screening is on your shortlist criteria, see how the hiremore AI platform handles ranking, explanation, and fairness auditing, and bring the seven questions. We built for buyers who ask them.
Ready to hire smarter?
Build structured pipelines, screen candidates with AI, and keep your team aligned from first application to final offer.
