An AI-powered ATS that simplifies shortlisting, tagging, and workflows - built for fast, scalable, and collaborative hiring.
Landing Pages
Copyright © 2026|hiremore AI
An AI-powered ATS that simplifies shortlisting, tagging, and workflows - built for fast, scalable, and collaborative hiring.




Every modern ATS runs resume parsing on millions of documents a day, and almost nobody outside engineering knows what it actually does. AI resume parsing is the automated extraction of structured data, names, skills, work history, education, from resume documents into candidate profiles. That’s it. It extracts. It doesn’t judge.
The confusion between parsing and screening causes real damage on both sides of the hiring desk. Recruiters blame “the AI” for rejections that were keyword filters. Candidates over-engineer resumes to beat parsers that were never grading them. Buyers pay screening prices for extraction features.
This guide is for recruiters, TA ops, and hiring leaders who want the honest version: what resume parsing can do, where it breaks, what accuracy numbers mean, and how to get clean data into your funnel.
- AI resume parsing extracts structured data from resumes; it does not score, rank, or reject candidates. Screening does that, and conflating the two leads to bad purchases and worse explanations.
- Modern parsers hit 85 to 95% field-level accuracy on clean, conventionally formatted resumes, and accuracy drops sharply on tables, two-column layouts, graphics, and scanned images.
- Parsing errors compound downstream: a missed skill or mangled date becomes a wrong search result and a wrong ranking input. Data quality at intake is a hiring quality issue.
- A candidate is never “rejected by the parser.” If qualified people are disappearing, audit the screening rules and knockout filters running on top of the parsed data.
- LLM-based parsing has lifted accuracy on messy layouts meaningfully, but it introduces a new failure mode: confident-sounding extraction errors that look right and aren’t.
AI resume parsing is the automated extraction of structured information, contact details, work history, skills, education, certifications, from resume files into standardized database fields that an ATS can store and search.
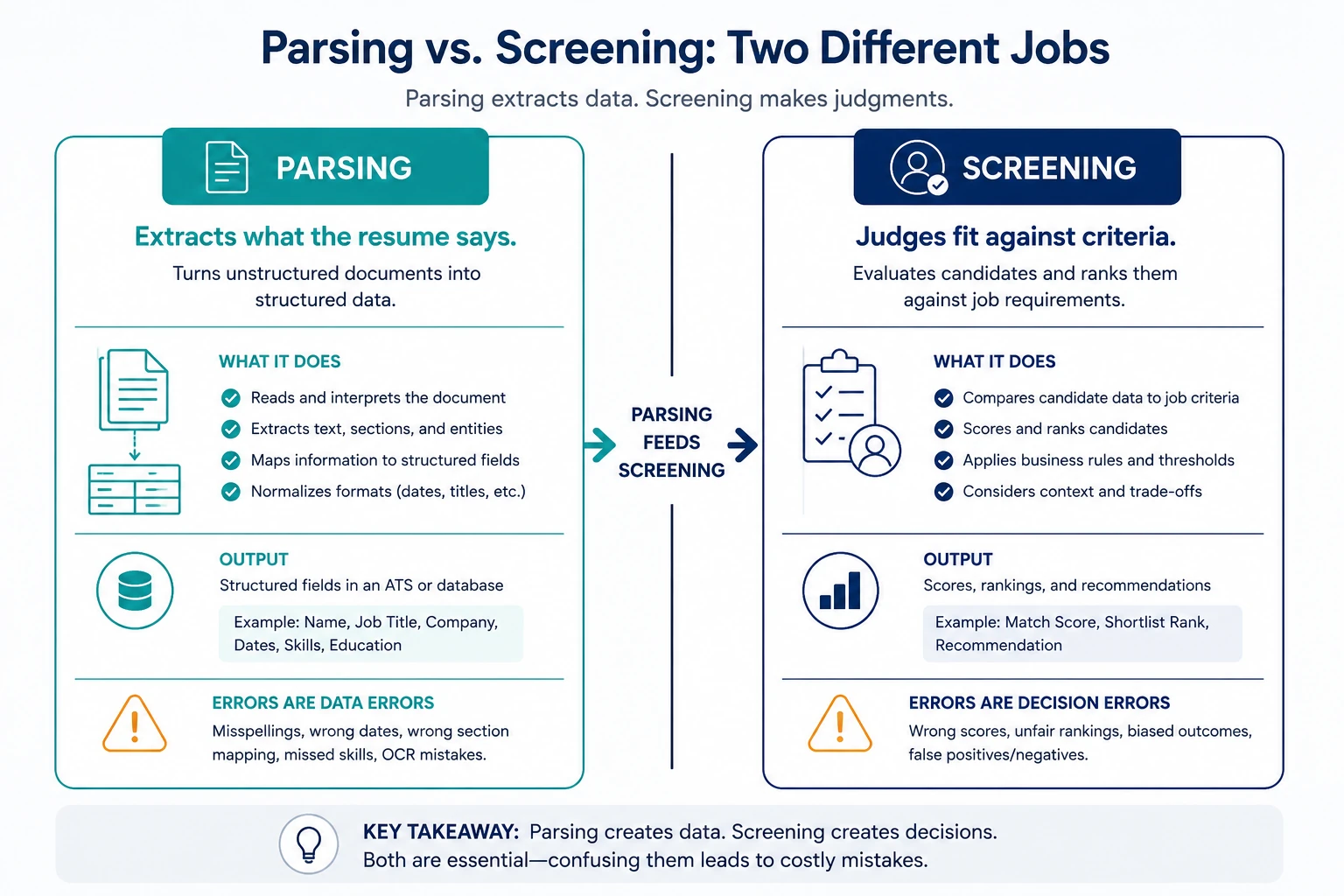
The critical distinction is parsing versus screening. Parsing answers “what does this resume say?” Screening answers “how well does this person fit the role?” Parsing produces data. Screening produces judgments. How AI resume screening works (and how to get it right) covers the judgment side in full — this article stays on the extraction side. They’re usually bundled in the same product, which is why everyone blurs them, but they fail differently, get regulated differently, and should be evaluated differently.
A parser that misreads a date produces a data error you can fix. A screening rule that auto-rejects on that bad date produces a decision error a candidate experiences. When candidates talk about “beating the ATS,” they’re almost always describing screening filters, not parsing.
Entity recognition: identifying that “Senior Backend Engineer, Acme, 2021 to 2024” is a job title, an employer, and a date range.Normalization: converting “Jan ’21”, “01/2021”, and “January 2021” into one standard date format.Field-level accuracy: the share of individual extracted fields that match what the resume actually says.Parsing matters because it’s the data foundation of every downstream hiring feature: search, matching, ranking, and analytics all consume parsed data, and they’re all only as good as the extraction underneath.
Think of what happens to one resume in a modern funnel. The parser extracts a profile. Search indexes the skills. The ranking model scores against criteria — for a full look at how that scoring works, see AI-driven candidate ranking: how it works. Analytics counts the candidate in funnel metrics. A parsing miss at step one, say a skills section in a sidebar the parser skipped, silently corrupts all four. The candidate is unfindable in search, underscored in ranking, and miscounted in your data.
Scale makes this material. At 250 applications per posting and a 90% field accuracy rate, you’re carrying parsing errors on thousands of fields across a single hiring cycle. Most are harmless. The ones that aren’t, missed certifications in healthcare, mangled work history for career changers, cost you exactly the candidates that are hardest to replace.
The honest limitation: parsing is genuinely hard because resumes are adversarially diverse. There’s no standard format, candidates optimize for human eyes, and creative layouts punish machines. Perfect parsing doesn’t exist. Managed parsing does.
📊 Key Stat: Modern parsers reach 85 to 95% field-level accuracy on conventionally formatted resumes. On two-column layouts, tables, and scanned documents, accuracy commonly drops 15 to 30 points, which is why parser choice and fallback review both matter.
The primary benefit is speed with structure: parsing converts a 250-resume pile into a searchable, comparable database in minutes, eliminating manual data entry that used to consume 5 to 10 minutes per candidate.
Instant structured profiles. Manual profile creation takes 5 to 10 minutes per candidate. Parsing does it in under 2 seconds, which at 250 applicants is roughly 30 recruiter hours saved per requisition before anyone makes a judgment.
Searchable talent pools. Parsed skills, titles, and locations make your historical applicant base queryable. Teams that re-mine parsed silver-medalist pools fill 10 to 20% of roles without new sourcing spend.
Cleaner analytics. Funnel metrics, source reports, and diversity statistics all depend on consistent candidate data. Parsing standardizes at intake, which is the cheapest place to fix data.
Better candidate experience. Parse-and-prefill application forms cut application time dramatically. Forms that auto-fill from an uploaded resume see measurably higher completion rates than ask-everything-again forms, and candidates notice the respect for their time.
| Aspect | Manual Data Entry | AI Resume Parsing |
|---|---|---|
| Time per profile | 5 to 10 minutes | Under 2 seconds |
| Consistency | Varies by person and day | Same rules every document |
| Searchability | Depends on entry discipline | Standardized fields, full coverage |
| Application forms | Candidate retypes everything | Prefilled from upload |
| Error pattern | Random human typos | Systematic, auditable, fixable |
💡 Pro Tip: Parsing errors are systematic, which is good news: they repeat, so they’re findable. Audit a sample of 50 parsed profiles quarterly against the source documents and you’ll catch most failure patterns before they distort a quarter of data.
Parsing runs as a pipeline: extract text from the document, detect sections, recognize entities like titles and dates, normalize them into standard formats, and write a structured profile to the ATS.
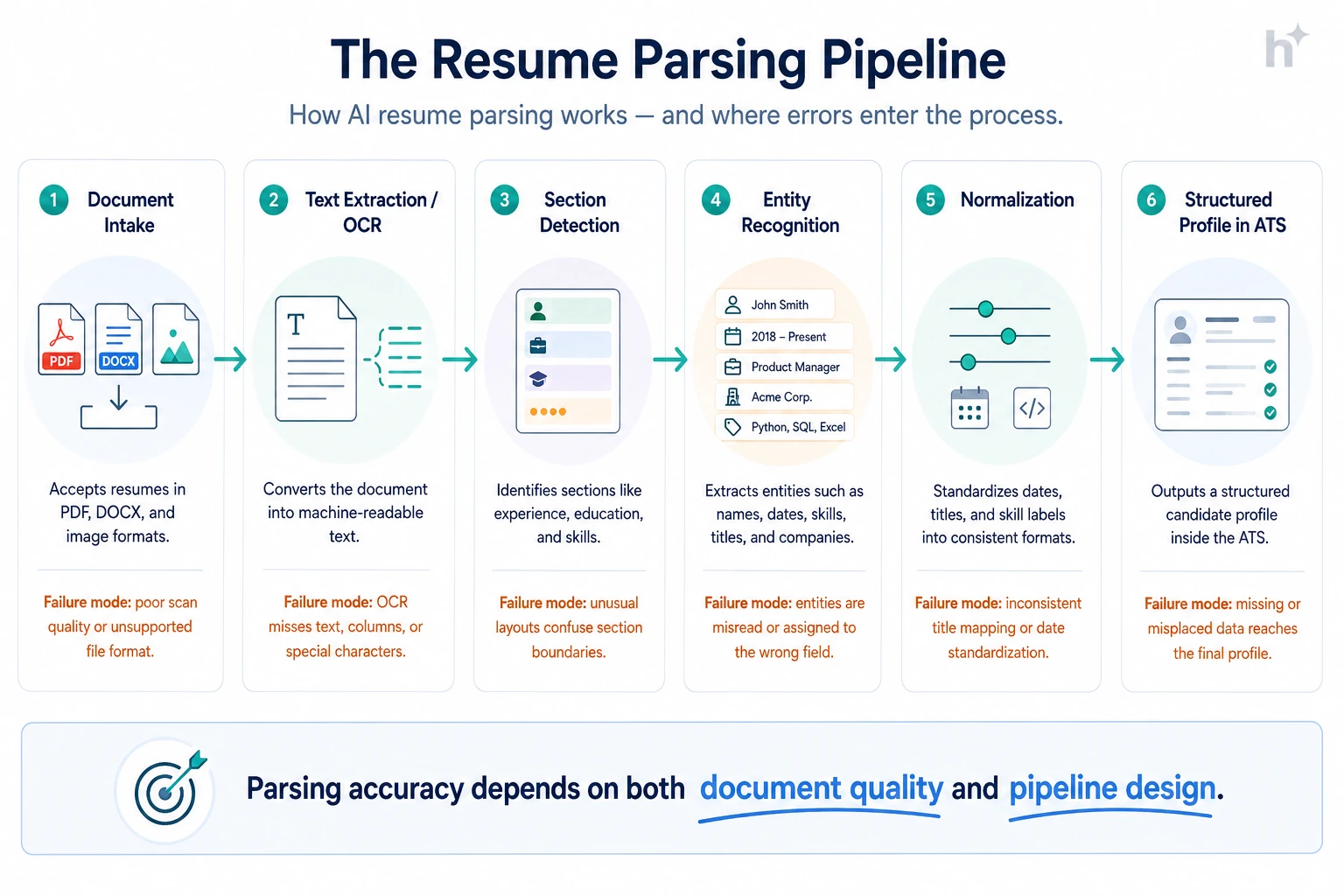
Input: The raw file: PDF, DOCX, sometimes an image or scan.
Process: Digital documents yield text directly; scans and images go through optical character recognition (OCR). This stage is where layout does its damage: two-column resumes can interleave unrelated text, and tables can scramble reading order.
Output: A linear text stream, hopefully in the right order.
Input: The extracted text.
Process: Models segment the text into sections (experience, education, skills) and tag entities within them: employer names, job titles, date ranges, degrees, certifications. Modern LLM-based parsers handle unconventional phrasing far better than the regex-and-dictionary parsers of a decade ago.
Output: Labeled entities with confidence scores.
Input: Tagged entities.
Process: Dates standardize to one format, titles map to a taxonomy, skills deduplicate against a skills ontology, and low-confidence fields get flagged for human review rather than silently guessed.
Output: A structured candidate profile in the ATS, with confidence flags where the parser wasn’t sure.
| Pipeline Stage | What Can Go Wrong | Mitigation |
|---|---|---|
| Text extraction | Column interleaving, OCR noise on scans | Layout-aware extraction, scan quality thresholds |
| Entity recognition | Unusual titles, overlapping roles, gaps | LLM-based models, confidence scoring |
| Normalization | Ambiguous dates, non-standard degrees | Flag-don’t-guess policy, human review queue |
The single most impactful practice is configuring low-confidence fields to flag for review instead of silently guessing, which converts invisible data corruption into a visible 2-minute fix.
Flag, don’t guess. Before: the parser guesses on a smudged date and a candidate shows a 3-year gap that doesn’t exist. After: sub-threshold confidence routes the field to a review queue; recruiters fix flagged fields in seconds during normal review.
Keep the original document one click away. Before: recruiters trust the parsed profile and miss what the parser missed. After: the source resume renders beside the profile; trust-but-verify becomes the default workflow and parse misses stop costing candidates.
Test your parser on your actual applicant mix. Before: vendor accuracy claims based on clean English-language corpora. After: a 100-resume sample from your own flow, including your real share of scans, creative layouts, and international formats. Accuracy on your mix is the only number that matters.
Don’t punish candidates for your parser. Before: application instructions demanding “no tables, no columns, PDF only” push formatting work onto candidates. After: a parser that handles modern layouts plus prefill-with-edit forms. Completion rates rise and you stop selecting for ATS-formatting knowledge instead of job skills.
| Condition | Recommended Action | Expected Outcome |
|---|---|---|
| High share of scanned/image resumes | OCR quality gate + review queue | Garbage profiles stop entering the funnel |
| International hiring | Test date/degree normalization per region | Fewer false gaps and credential misses |
| Candidates report “lost” applications | Audit prefill and parse-fail handling | Application completion recovers |
| Search returns weak matches | Re-parse historical pool with current parser | Talent pool searchability restored |
⚠️ Watch Out: Never let parsed data feed an auto-reject rule without a confidence check. An auto-rejection caused by a parsing error is indistinguishable, to the candidate and to a regulator, from a screening decision, and “the parser misread the date” is an admission, not a defense.
The most common failure mode is layout, not language: two-column designs, tables, text boxes, and graphics break reading order long before vocabulary becomes a problem.
Designer resumes with sidebars and infographics parse worst precisely when they impress humans most. Solution: layout-aware extraction models, plus side-by-side source view so recruiters catch what extraction dropped.
OCR on a phone photo of a printed resume produces noisy text that poisons every downstream stage. Solution: quality thresholds that route bad scans to a manual queue, and application flows that accept LinkedIn import as an alternative path.
“2019 to present” alongside a second concurrent role, or fiscal-year formats, generate false gaps and false overlaps. Solution: normalization rules that preserve ambiguity flags instead of forcing a guess, surfaced in the recruiter view.
LLM-based parsers handle messy input brilliantly and occasionally fabricate a plausible-looking field, a tidy job title that isn’t on the page. Solution: extraction grounded with source-position references, spot audits comparing fields to the document, and confidence display in the UI.
Parsing improvements pay off in recovered candidates and recovered time, and the gains concentrate wherever document quality is worst.
Global staffing firm, 1M+ resumes/year. Problem: legacy parser failed hard on non-Western date formats and two-column CVs common in European markets, producing false employment gaps. Intervention: switched to an LLM-based parser with flag-don’t-guess normalization and re-parsed the active pool. Measured outcome: field-level accuracy on the European sample rose from 71% to 91%, and recruiter complaints about “broken profiles” fell 80% in a quarter.
Hospital network, credential-heavy hiring. Problem: missed certifications in parsing meant qualified nurses didn’t surface in license-filtered searches. Intervention: added a certification-specific extraction pass with a human review queue for low-confidence credentials. Measured outcome: license-search recall improved 23%, directly surfacing candidates who were already in the database.
High-volume retailer, mobile-first applicants. Problem: 40% of applications arrived as phone photos of printed resumes; OCR noise made profiles useless. Intervention: scan-quality gating plus a 3-question structured form fallback when parsing failed. Measured outcome: usable profile rate rose from 61% to 94%, with no added candidate effort for clean documents.
💡 Pro Tip: The hospital case generalizes: if a specific field class is business-critical (licenses, clearances, certifications), give it a dedicated extraction pass and review queue. General-purpose parsing treats all fields equally; your hiring doesn’t.
The most important parsing metric is field-level accuracy on your own document mix, measured by sampling parsed profiles against source resumes.
Field-level accuracy. Definition: share of extracted fields matching the source document; the core quality measure. Calculation: audit a random sample of 50 to 100 profiles quarterly; correct fields ÷ total fields × 100. Target benchmark: 90%+ on your real mix; investigate any field class below 85%.
Parse failure rate. Definition: share of documents producing no usable profile. Calculation: failed parses ÷ total documents × 100. Target benchmark: under 3% with a fallback path for failures.
Flag-and-review rate. Definition: share of fields routed to human review on low confidence; measures honesty of the pipeline. Calculation: flagged fields ÷ total fields × 100. Target benchmark: 2 to 8%. Near zero means the parser is guessing; very high means thresholds need tuning.
Search recall on known candidates. Definition: whether candidates you know are in the pool actually surface in relevant searches; the end-to-end data quality test. Calculation: seeded searches for 20 known profiles quarterly; found ÷ seeded × 100. Target benchmark: 95%+.
Prefill completion lift. Definition: application completion rate with parse-prefilled forms versus manual entry. Calculation: A/B or before/after completion comparison. Target benchmark: meaningful lift over manual baseline; if absent, the prefill UX needs work.
| Metric | What It Measures | How to Calculate | Target Benchmark |
|---|---|---|---|
| Field accuracy | Extraction quality | Sampled audit vs source docs | 90%+ on own mix |
| Parse failure rate | Pipeline robustness | Failures ÷ documents | < 3% |
| Flag-and-review rate | Pipeline honesty | Flagged ÷ total fields | 2 to 8% |
| Search recall | Downstream data quality | Seeded search test | 95%+ |
| Prefill lift | Candidate experience | Completion A/B | Clear positive lift |
The highest-severity risk is silent data corruption feeding automated decisions: a parsing error that becomes a knockout rejection turns a data bug into a candidate-facing harm.
Parsing errors as rejection causes. Knockout rules running on parsed fields (years of experience, certifications) will reject on extraction mistakes. Gate automated rules behind confidence thresholds and keep humans on borderline calls.
Format discrimination. Parsers that fail on non-Western CV conventions or older candidates’ formatting habits create disparate outcomes nobody chose. Test on representative documents and monitor pass rates by source and geography.
Vendor accuracy theater. “99% accuracy” measured on clean test corpora tells you nothing about your scanned-photo, two-column reality. Demand testing on your sample before buying. AI recruitment tools: what to look for before buying gives you the full evaluation framework beyond just parsing accuracy.
Stale historical profiles. Pools parsed years ago with weaker parsers underrepresent those candidates in today’s searches. Re-parse historical data when you upgrade parsers; it’s cheap and recovers real people.
⚠️ Watch Out: The riskiest sentence in parsing is “the system handled it.” Every silent guess is a potential wrong rejection. Insist on confidence flags, review queues, and a one-click source document view.
Parsing is being absorbed into multimodal document understanding: models that read layout, text, and context together, which is steadily closing the gap on the formats that break traditional pipelines.
Multimodal layout understanding. Vision-language models read a two-column resume the way a human does, by seeing it. The formats that punished parsing for two decades are becoming tractable, with accuracy on creative layouts improving fastest.
Skills ontologies over keyword lists. Parsed skills increasingly map into standardized taxonomies, making “Kubernetes” findable under “container orchestration.” Search recall improves without candidates gaming keywords.
Resume-free structured intake. Some high-volume employers are skipping the document entirely: structured profile capture and verified credential APIs replace parsing where the resume adds little. Parsing won’t disappear, but its monopoly on intake is ending.
AI resume parsing automatically extracts structured information, contact details, work history, skills, education, from resume files into database fields. It works as a pipeline: text extraction (with OCR for scans), section and entity recognition, then normalization into standard formats. It extracts what the resume says; it makes no judgment about candidate fit.
No. Parsing only extracts data. Rejections come from screening rules and knockout filters that run on top of parsed data, or from human reviewers. A parsing error can feed a wrong screening outcome, which is why well-run teams gate automated rules behind confidence checks and keep humans on borderline decisions.
Modern parsers reach 85 to 95% field-level accuracy on cleanly formatted documents, and meaningfully less on tables, two-column layouts, graphics, and scanned images. The only accuracy number that matters is performance on your own applicant mix, which you can measure by auditing a 50-resume sample against source documents.
Less than the internet claims. Modern parsers handle standard professional formats fine, including modest design. The genuinely risky choices are text rendered inside images or graphics, and photographed printouts of paper resumes. A clean PDF with real text covers the rest.
Parsing extracts what a resume says into structured data. Screening judges how well that data fits a role’s criteria, producing scores, rankings, or pass/fail outcomes. Parsing errors are data errors; screening errors are decision errors. They’re bundled in most products but should be evaluated, and audited, separately.
Pull 100 resumes representing your real applicant mix, including your actual share of scans, creative layouts, and international formats. Have the vendor parse them, then audit field-level accuracy against the source documents, paying special attention to your business-critical fields like certifications. Accuracy on your mix beats any benchmark claim.
AI resume parsing is the unglamorous foundation under every smart hiring feature: extraction, not judgment, and only as good as its honesty about uncertainty. Treat it as a data quality discipline — flag-don’t-guess, source documents one click away, quarterly audits on your own mix — and everything built on top gets more trustworthy. Once parsing and screening are solid, the next step in the funnel is The complete guide to AI-powered interviews.
The tension to manage is automation versus accountability: every silent guess saves a second and risks a candidate. AI hiring automation: what to automate and what not to maps exactly where to draw that line across your full hiring stack. Confidence flags and review queues are how you keep the speed without inheriting the silent errors.
Want to see parsing done with the receipts showing? Explore how the hiremore AI platform pairs resume parsing with confidence scoring and side-by-side source review, so your team always knows what the AI read and what it wasn’t sure about.
Ready to hire smarter?
Build structured pipelines, screen candidates with AI, and keep your team aligned from first application to final offer.
