An AI-powered ATS that simplifies shortlisting, tagging, and workflows - built for fast, scalable, and collaborative hiring.
Landing Pages
Copyright © 2026|hiremore AI
An AI-powered ATS that simplifies shortlisting, tagging, and workflows - built for fast, scalable, and collaborative hiring.




Most ATS projects don’t fail at selection. They fail in the twelve weeks after the contract is signed, when data migration surprises, stalled workflow decisions, and rushed training turn a good platform into a resented one. ATS implementation is the structured process of configuring, migrating, integrating, and rolling out a new applicant tracking system, and done well it takes a mid-market team 10 to 12 weeks.
This ATS implementation guide is written from the buyer’s side of the table, for TA ops leads, HR leaders, and the unlucky project owner who has to make it all work. You’ll get the 6-phase plan, the data migration traps that cause most delays, and the go-live criteria that separate a launch from a mess.
The stakes are simple: the same platform, implemented two different ways, produces either 90% adoption or a team quietly working around the system in spreadsheets. Implementation, not selection, decides which.
- ATS implementation runs in 6 phases: planning, data migration, workflow configuration, integrations, training and pilot, then go-live with stabilization. Mid-market timelines run 10 to 12 weeks when decisions don’t stall.
- Data migration is the most common delay: plan a cleanup pass, migrate in a validated sample first, and never migrate everything blindly. Dirty data in the old system becomes dirty data with a new interface.
- The biggest timeline variable is buyer-side decision speed on workflows, not vendor speed. Pre-deciding your stage definitions and approval chains saves 2 to 3 weeks.
- Go-live needs written criteria: validated migration sample, every role-family workflow tested by a real recruiter, live training completed, and critical integrations working. Launching without them trades a fake deadline win for months of cleanup.
- Plan for a 2-week stabilization period post-launch with daily triage. Teams that staff it reach steady-state adoption roughly twice as fast as teams that declare victory on day one.
ATS implementation is the end-to-end process of standing up a new applicant tracking system: planning and governance, migrating candidate data, configuring workflows, connecting integrations, training users, and managing go-live.
It’s worth separating implementation from onboarding, because vendors blur them. Vendor onboarding is their checklist: account provisioning, admin training, template setup. Implementation is your project: deciding how hiring will actually run on the new system, moving your history into it safely, and getting humans to change daily habits.
The vendor drives maybe 30% of the outcome. The rest is decisions only your team can make: what your pipeline stages mean, which data is worth migrating, who approves offers, and what happens to the requisitions in flight during cutover.
Data migration: moving candidates, requisitions, and history from the old system into the new one, with field mapping and validation.Cutover: the moment new activity moves to the new system, with a plan for in-flight requisitions.Stabilization: the 1 to 2 weeks post-launch of daily issue triage before the project is actually done.Implementation quality matters because it, not platform quality, determines adoption: the same ATS produces 90% usage or spreadsheet workarounds depending entirely on how the twelve weeks after signing are run.
The pattern behind most “bad ATS” complaints is a rushed rollout. Data arrived dirty, so recruiters stopped trusting search. Workflows were copied from the vendor template instead of designed, so the system fought how the team actually hires. Training was a PDF, so everyone learned by frustration. None of that is the software’s fault, and all of it is permanent unless fixed deliberately later, at higher cost.
There’s also a compliance angle people miss. Candidate data migration touches privacy obligations: GDPR retention rules don’t pause because you switched vendors, and migrating data you had no basis to keep copies a liability into a new house. A migration is the cheapest moment you’ll ever have for a retention cleanup.
📊 Key Stat: Implementation timelines for mid-market ATS projects cluster at 2 to 4 months, and the single biggest variable in published post-mortems is buyer-side decision latency, not vendor effort. The project moves at the speed of your workflow decisions.
A structured rollout converts the implementation period from risk into leverage: clean data, workflows designed around your hiring, and a team that adopts the system because it visibly works on day one.
Trustworthy data from day one. A validated migration means search works, history is intact, and reports are credible immediately. Trust lost to dirty data in week one takes quarters to rebuild.
Workflows that match reality. Configuration designed from your actual hiring stages, including the messy exceptions, means recruiters don’t need workarounds, and workarounds are where adoption goes to die.
Faster time-to-value. Teams that run the 6-phase plan typically see automation savings (scheduling, status updates) within the first month post-launch, because automations were built and tested during the pilot rather than promised for “phase 2.”
A defensible compliance posture. Retention cleanup during migration, permission design during configuration, and audit trails verified before go-live. Doing these in-flight costs days; retrofitting costs months.
| Aspect | Rushed Rollout | Structured Rollout |
|---|---|---|
| Data | Migrated blind, trust collapses | Cleaned, sampled, validated |
| Workflows | Vendor templates, daily friction | Designed from real hiring stages |
| Training | PDF attachment | Role-based live sessions + pilot |
| Integrations | “Phase 2” (never) | Critical ones live at launch |
| Adoption at 90 days | 40 to 60%, workarounds everywhere | 85 to 95% |
💡 Pro Tip: Decide your pipeline stage definitions before the vendor kickoff call. It’s the single decision that blocks the most downstream work, and it requires zero vendor input. Teams that arrive at kickoff with stages agreed shave 2 to 3 weeks off the timeline.
Implementation runs through six overlapping phases: planning, data migration, workflow configuration, integrations, training with a pilot, and go-live with stabilization, totaling 10 to 12 weeks for most mid-market teams.
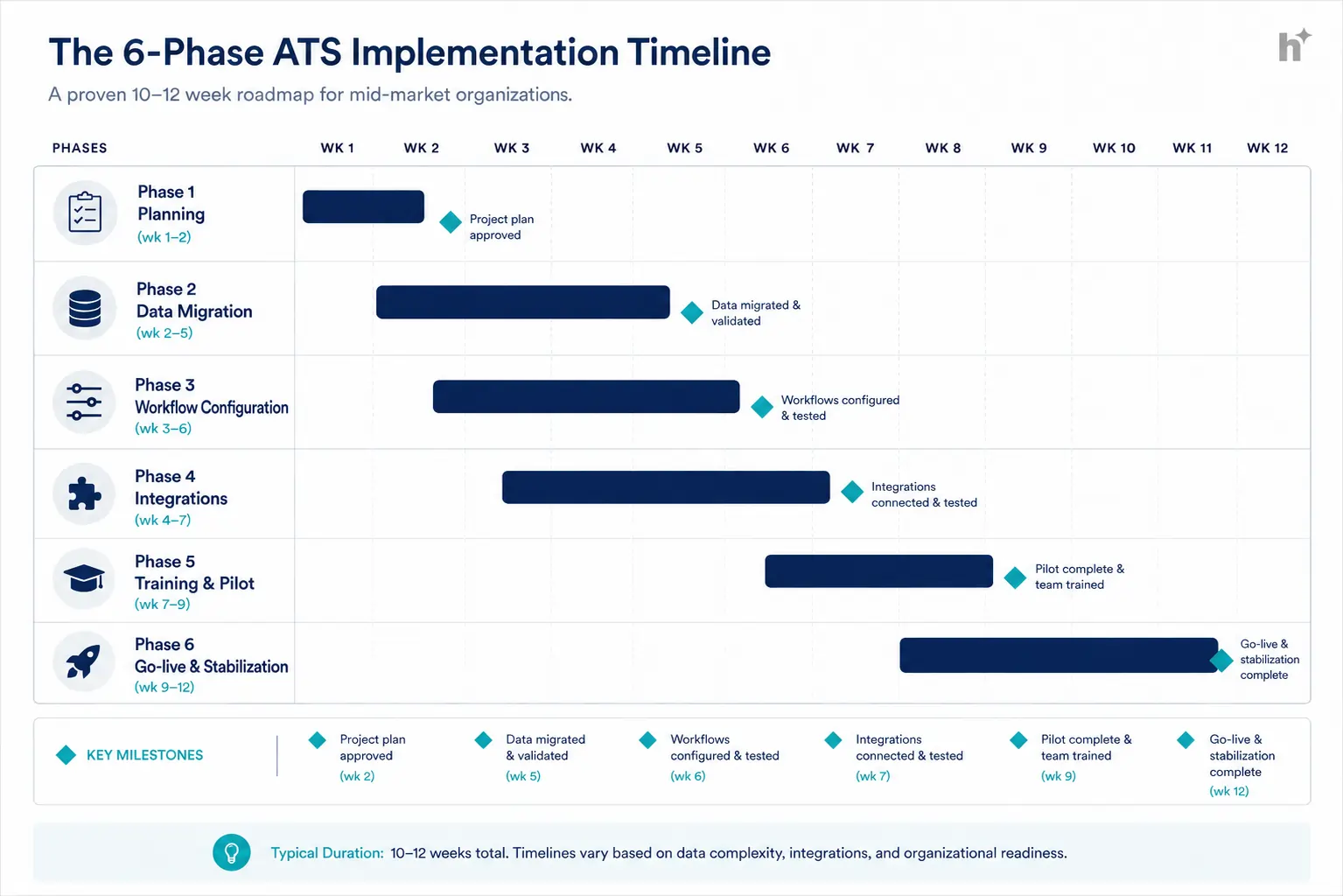
Input: The signed contract, your selection scorecard, and a named project owner with real authority.
Process: Define scope, decision-makers, and the weekly cadence. Pre-make the big decisions: pipeline stages per role family, approval chains, what data migrates, cutover strategy for in-flight requisitions. Write go-live criteria now, while nobody’s tempted to bend them.
Output: A project plan with owners, dates, and written go-live criteria.
Input: Your legacy data: candidates, requisitions, notes, documents, historical outcomes.
Process: Audit first: duplicates, stale records, retention violations. Decide what earns migration (a common cut: active pipelines plus 24 months of history). Map fields explicitly, migrate a 500-record sample, validate it manually, then run the full load.
Output: A clean, validated dataset in the new system, and a documented archive of what stayed behind.
Input: Your pre-decided stages, approval chains, and templates.
Process: Configure pipelines per role family, automation rules, email templates, scorecards, and permissions. Build your three most common hiring scenarios end-to-end and run fake candidates through them.
Output: Working workflows tested with realistic scenarios, not just configured screens.
Input: Your stack list, prioritized: calendar and email first, HRIS second, assessments and boards third.
Process: Connect, then test bidirectionally with real scenarios: does a hire flow to the HRIS correctly? Does a declined slot rebook? Integration testing with fake data is where silent failures hide.
Output: Critical integrations verified live; nice-to-haves scheduled, not forgotten.
Input: Configured system, validated data, connected integrations.
Process: Role-based live training (recruiters, hiring managers, interviewers get different sessions), then a 2-week pilot: 2 to 3 live requisitions run entirely in the new system by your most demanding recruiters. Fix what they find.
Output: A battle-tested configuration and internal champions who’ve actually hired in the system.
Input: The written go-live criteria from Phase 1, honestly assessed.
Process: Cut over new requisitions, run legacy ones to completion in the old system (parallel running beats mid-flight migration for most teams), and staff a daily 30-minute triage for 2 weeks. Publish wins weekly: hours saved, time-to-schedule drops.
Output: A stable system, visible early wins, and a closed project, actually closed, with a 30-day review scheduled.
The single most impactful practice is writing go-live criteria during planning and refusing to launch until they’re met, because every broken launch traces to a deadline beating a checklist.
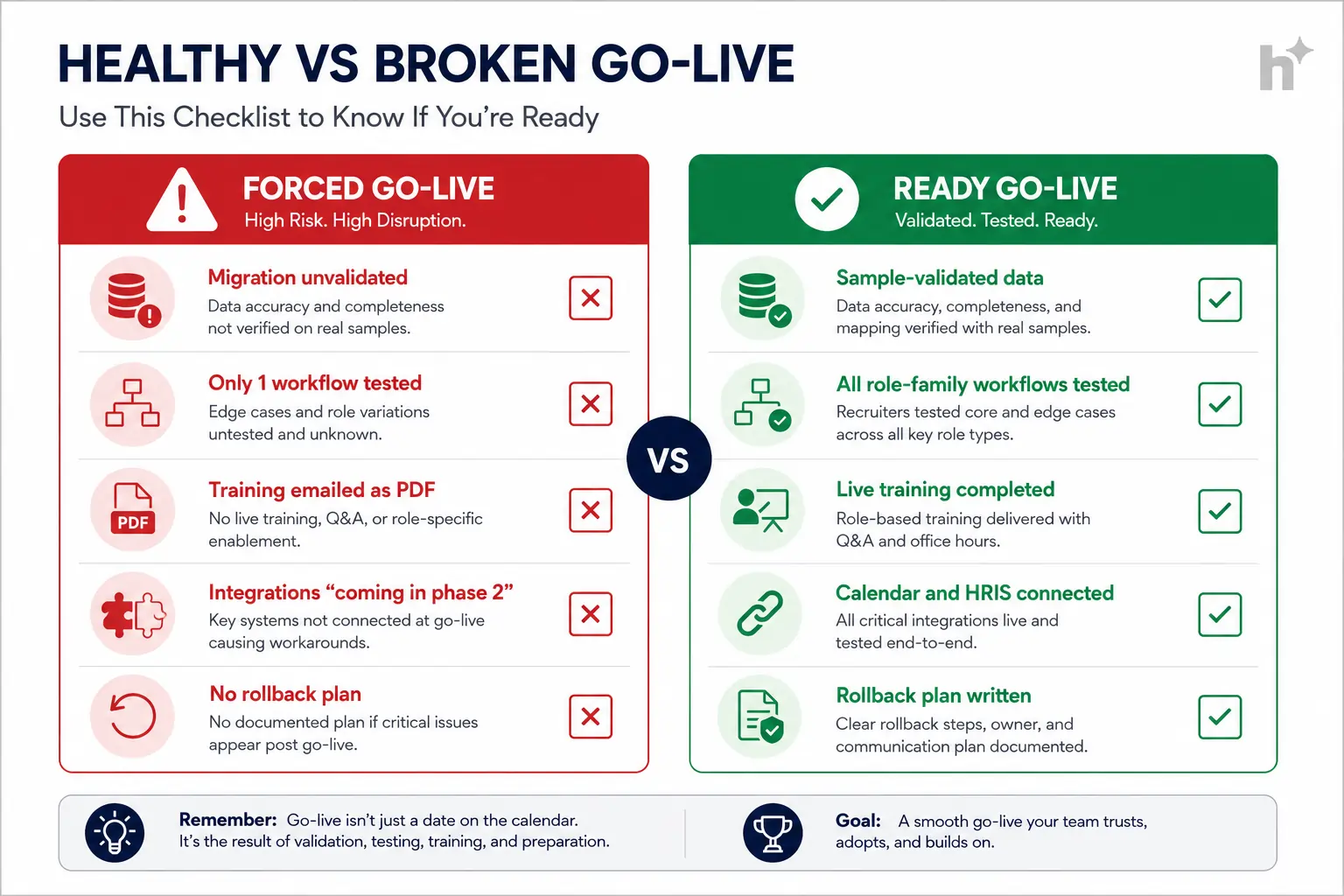
Write go-live criteria in week one. Before: launch dates drive readiness theater and a broken day one. After: four written criteria (validated data sample, tested workflows per role family, live training done, critical integrations verified) gate the launch. Slipping one week beats cleaning up for one quarter.
Migrate a sample before the full load. Before: 80,000 records migrate overnight and field-mapping errors surface for months. After: a 500-record sample validated manually catches mapping issues when they cost an afternoon.
Pilot with your toughest recruiters. Before: the project team demos to itself and declares readiness. After: your most skeptical, highest-volume recruiters run real requisitions for two weeks. What survives them survives anyone.
Run legacy requisitions to completion. Before: mid-flight candidates get migrated mid-process and experience glitches at the worst moment. After: new reqs start in the new system, old ones finish in the old. Two systems for six weeks is calmer than one broken candidate experience.
Publish wins weekly post-launch. Before: complaints dominate the narrative because friction is loud and savings are silent. After: a weekly note with concrete numbers (scheduling time down 60%, 14 hours saved) gives adoption its own momentum.
| Condition | Recommended Action | Expected Outcome |
|---|---|---|
| Legacy data is a known mess | Add a 2-week cleanup before migration | Trustworthy search and reports at launch |
| Hiring managers resist new tools | Email-native approvals + 20-minute role training | HM adoption above 70% |
| Hard external deadline (contract end) | Cut scope, not testing: fewer integrations at launch | Stable core beats broken everything |
| Multi-country rollout | Phase by region, lead with the most standard one | Lessons compound instead of multiplying |
⚠️ Watch Out: The most dangerous week is the one where the old system’s contract expires before the new system passes its criteria. Negotiate a 60-day overlap on the legacy contract upfront. It’s cheap insurance against the forced-launch trap.
The most common challenge is decision stall: workflow questions sitting unanswered for weeks while the vendor waits and the timeline quietly slides.
“What are our offer approval steps?” turns into a three-week email thread. Solution: a standing weekly decision meeting with a named decider per area, and a 48-hour default rule: undecided items get the project owner’s call.
Duplicates, half-filled records, and a decade of inconsistent stage usage surface mid-migration. Solution: audit before you migrate, set an explicit cut (active + 24 months is common), and archive the rest in queryable cold storage instead of dragging it along.
The HRIS connector exists but doesn’t sync the fields you need. Solution: test the actual field-level sync in week 4, not week 10, and keep a manual-process fallback documented for anything that slips past launch.
One webinar, three weeks before go-live, retained by nobody. Solution: role-based sessions inside two weeks of launch, a pilot that forces real use, and 2-minute task videos embedded where the work happens.
Structured implementations consistently land in 10 to 12 weeks with adoption above 85%, and the failures cluster around skipped validation and forced launch dates.
Manufacturing group, 4 sites, 250 hires/year. Problem: previous ATS rollout had collapsed: blind migration filled the system with 60% duplicate or dead records and recruiters reverted to spreadsheets within a month. Intervention: re-implementation with a data audit, an active-plus-24-months migration cut, and a 500-record validated sample before full load. Measured outcome: go-live in 11 weeks, search trusted from day one, and 91% recruiter weekly adoption at 60 days.
Tech scale-up, 120 hires/year. Problem: hard deadline: legacy contract ended in 9 weeks. Intervention: scope cut by criteria, not by testing: launched with calendar/email integration live, HRIS sync running manually for 3 weeks, all workflows piloted. Measured outcome: launched on time and stable; the deferred HRIS connector went live in week 12 with zero data issues.
Healthcare network, compliance-heavy. Problem: GDPR retention obligations made blind migration legally risky: years of candidate data with expired consent. Intervention: retention cleanup as Phase 2’s first step, deleting expired-consent records and documenting the basis for everything migrated. Measured outcome: 38% smaller migration, a written compliance trail, and an estimated week of audit response time saved per quarter.
💡 Pro Tip: The scale-up case carries the rule worth stealing: when deadlines compress, cut scope, never testing. A stable core with one deferred integration beats a complete launch where nothing’s verified.
The most telling metric is weekly active adoption at 60 days, because it captures whether the implementation produced a system people actually work in.
Weekly active adoption. Definition: share of intended users working in the system weekly; the headline outcome. Calculation: weekly actives ÷ licensed users, split recruiters vs hiring managers. Target benchmark: 90%+ recruiters, 70%+ hiring managers by day 60.
Migration accuracy. Definition: share of migrated records with correct, complete critical fields. Calculation: manual audit of a 200-record random sample post-load. Target benchmark: 98%+ on critical fields; below that, fix mapping before go-live.
Timeline variance. Definition: actual vs planned phase completion; the project health signal. Calculation: days late per phase, tracked weekly. Target benchmark: under 15% total slip; persistent slippage almost always means decision stall, not vendor delay.
Time-to-first-value. Definition: days from go-live to the first measured automation win. Calculation: timestamp of first verified saving (e.g., scheduling cycle under 24 hours). Target benchmark: within 30 days of launch.
Support ticket burn-down. Definition: internal issue volume during stabilization; measures launch quality. Calculation: tickets per week, weeks 1 to 4 post-launch. Target benchmark: 60%+ decline from week 1 to week 4.
| Metric | What It Measures | How to Calculate | Target Benchmark |
|---|---|---|---|
| Weekly adoption | Real usage | Actives ÷ licensed at day 60 | 90% recruiters / 70% HMs |
| Migration accuracy | Data trust | 200-record sample audit | 98%+ critical fields |
| Timeline variance | Project health | Days late per phase | < 15% total |
| Time-to-first-value | Payoff speed | Days to first verified win | < 30 days |
| Ticket burn-down | Launch quality | Weekly tickets, wks 1-4 | 60%+ decline |
The highest-severity risk is the forced go-live: launching to hit a date with unvalidated data and untested workflows, which converts a one-week delay into a one-quarter cleanup and a trust deficit that outlasts both.
The forced launch. Deadline pressure plus sunk-cost momentum overrides the checklist. Mitigation: written criteria from week one, a negotiated legacy-system overlap, and a project owner empowered to slip a week.
Blind migration. Everything moves, nothing’s validated, and the new system inherits a decade of rot plus fresh mapping errors. Mitigation: audit, cut, sample, validate, then load.
Compliance carry-over. Migrating candidate data past its retention basis copies liability into a new system with better logging of your violation. Mitigation: make retention cleanup the first migration step and document the basis for what moves.
Champion dependency. The whole project lives in one person’s head, and they resign in week 8. Mitigation: a decision log and a deputy from day one. Boring, and it saves projects.
⚠️ Watch Out: If your implementation plan has no written go-live criteria, you don’t have a plan. You have a date with a hope attached.
Implementation itself is getting AI assistance: migration field-mapping, workflow scaffolding from plain-language descriptions, and in-app guidance are compressing timelines at the low end.
AI-assisted migration mapping. Models now propose field mappings and flag anomalies in legacy data, cutting the mapping grind meaningfully. Validation stays human: the sample audit isn’t going anywhere.
Configuration from description. Describing your hiring stages in plain language and getting a draft workflow configuration is becoming standard vendor tooling, turning blank-page setup into edit-and-approve.
Embedded adoption analytics. Platforms increasingly ship adoption dashboards: who’s active, which features are ignored, where workarounds form. Implementation success is becoming measurable inside the product instead of through surveys.
Lightweight platforms with minimal migration: 2 to 6 weeks. Mid-market with data migration and integrations: 10 to 12 weeks. Enterprise with multiple regions and systems: 4 to 9 months. The biggest variable is buyer-side decision speed on workflows and data, which is why pre-deciding pipeline stages saves 2 to 3 weeks.
Six phases: planning and governance, data migration, workflow configuration, integrations, training with a live pilot, and go-live with a stabilization period. The two most commonly skipped, sample-validated migration and a real pilot, are the two that prevent the most post-launch pain.
Audit first, then cut: a common rule is active pipelines plus 24 months of history, with the rest archived. Map fields explicitly, migrate a 500-record sample, validate it manually against the source, then run the full load. And use the moment for retention compliance cleanup, since migrating data past its legal basis copies liability into the new system.
For most teams, yes, briefly: start all new requisitions in the new system and let in-flight ones finish in the old, typically a 4 to 8 week overlap. It costs some double-checking and spares mid-process candidates from cutover glitches. Negotiate the legacy contract overlap before you need it.
Three causes dominate: blind data migration that destroys trust in the system, workflow configuration copied from templates instead of designed around real hiring, and forced go-lives that hit a date with untested setups. All three are buyer-side and preventable, which is the good news.
One named owner with authority to make calls, typically a TA ops lead or HR project manager, supported by a weekly decision forum and a deputy who shares context. Vendor project managers coordinate their side; they can’t make your workflow decisions, and waiting for consensus is the top schedule killer.
ATS implementation rewards the unglamorous virtues: decisions made early, data validated in samples, workflows tested by skeptics, and a launch gated by criteria instead of a calendar. Run the six phases honestly and the platform you carefully selected becomes the platform your team actually uses.
The permanent tension is speed versus stability, and the resolution is scope: when time compresses, launch fewer things fully tested rather than everything half-verified.
If you’re planning a migration and want a platform built to come up clean, with AI-assisted setup, native automations, and adoption analytics out of the box, take a look at how hiremore AI handles ATS implementation. Bring your messiest legacy data questions. Those are our favorite kind.
Ready to hire smarter?
Build structured pipelines, screen candidates with AI, and keep your team aligned from first application to final offer.
